
使用 Python 掌握机器学习:基础和关键概念
 浏览:567
浏览:567
In today's era of Artificial Intelligence (AI), scaling businesses and streamlining workflows has never been easier or more accessible. AI and machine learning equip companies to make informed decisions, giving them a superpower to predict the future with just a few lines of code. Before taking a significant risk, wouldn't knowing if it's worth it be beneficial? Have you ever wondered how these AIs and machine learning models are trained to make such precise predictions?
In this article, we will explore, hands-on, how to create a machine-learning model that can make predictions from our input data. Join me on this journey as we delve into these principles together.
This is the first part of a series on mastering machine learning, focusing on the foundations and key concepts. In the second part, we will dive deeper into advanced techniques and real-world applications.
Introduction:
Machine Learning (ML) essentially means training a model to solve problems. It involves feeding large amounts of data (input-data) to a model, enabling it to learn and discover patterns from the data. Interestingly, the model's accuracy depends solely on the quantity and quality of data it is fed.
Machine learning extends beyond making predictions for enterprises; it powers innovations like self-driving cars, robotics, and much more. With continuous advancements in ML, there's no telling what incredible achievements lie ahead - it's simply amazing, right?
There's no contest as to why Python remains one of the most sought-after programming languages for machine learning. Its vast libraries, such as Scikit-Learn and Pandas, and its easy-to-read syntax make it ideal for ML tasks. Python offers a simplified and well-structured environment that allows developers to maximize their potential. As an open-source programming language, it benefits from contributions worldwide, making it even more suitable and advantageous for data science and machine learning.
Fundamentals Of Machine Learning
Machine Learning (ML) is a vast and complex field that requires years of continuous learning and practice. While it's impossible to cover everything in this article, let's look into some important fundamentals of machine learning, specifically:
- Supervised Machine Learning From its name, we can deduce that supervised machine learning involves some form of monitoring or structure. It entails mapping one function to another; that is, providing labeled data input (i) to the machine, explaining what should be done (algorithms), and waiting for its output (j). Through this mapping, the machine learns to predict the output (j) whenever an input (i) is fed into it. The result will always remain output (j). Supervised ML can further be classified into:
Regression: When a variable input (i) is supplied as data to train a machine, it produces a continuous numerical output (j). For example, a regression algorithm can be used to predict the price of an item based on its size and other features.
Classification: This algorithm makes predictions based on grouping by determining certain attributes that make up the group. For example, predicting whether a product review is positive, negative, or neutral.
- Unsupervised Machine Learning Unsupervised Machine Learning tackles unlabeled or unmonitored data. Unlike supervised learning, where models are trained on labeled data, unsupervised learning algorithms identify patterns and relationships in data without prior knowledge of the outcomes. For example, grouping customers based on their purchasing behavior.
Setting Up Your Environment
When setting up your environment to create your first model, it's essential to understand some basic steps in ML and familiarize yourself with the libraries and tools we will explore in this article.
Steps in Machine Learning:
- Import the Data: Gather the data you need for your analysis.
- Clean the Data: Ensure your data is in good and complete shape by handling missing values and correcting inconsistencies.
- Split the Data: Divide the data into training and test sets.
- Create a Model: Choose your preferred algorithm to analyze the data and build your model.
- Train the Model: Use the training set to teach your model.
- Make Predictions: Use the test set to make predictions with your trained model.
- Evaluate and Improve: Assess the model's performance and refine it based on the outputs.
Common Libraries and Tools:
NumPy: Known for providing multidimensional arrays, NumPy is fundamental for numerical computations.
Pandas: A data analysis library that offers data frames (two-dimensional data structures similar to Excel spreadsheets) with rows and columns.
Matplotlib: Matplotlib is a two-dimensional plotting library for creating graphs and plots.
Scikit-Learn: The most popular machine learning library, providing all common algorithms like decision trees, neural networks, and more.
Recommended Development Environment:
Standard IDEs such as VS Code or terminals may not be ideal when creating a model due to the difficulty in inspecting data while writing code. For our learning purposes, the recommended environment is Jupyter Notebook, which provides an interactive platform to write and execute code, visualize data, and document the process simultaneously.
Step-by-Step Setup:
Download Anaconda:
Anaconda is a popular distribution of Python and R for scientific computing and data science. It includes the Jupyter Notebook and other essential tools.
Download Anaconda from this link.
Install Anaconda:
Follow the installation instructions based on your operating system (Windows, macOS, or Linux).
After the installation is complete, you will have access to the Anaconda Navigator, which is a graphical interface for managing your Anaconda packages, environments, and notebooks.
Launching Jupyter Notebook:
Open the Anaconda Navigator
In the Navigator, click on the "Environments" tab.
Select the "base (root)" environment, and then click "Open with Terminal" or "Open Terminal" (the exact wording may vary depending on the OS).
In the terminal window that opens, type the command jupyter notebook and press Enter.
This command will launch the Jupyter Notebook server and automatically open a new tab in your default web browser, displaying the Jupyter Notebook interface.
Using Jupyter Notebook:
The browser window will show a file directory where you can navigate to your project folder or create new notebooks.
Click "New" and select "Python 3" (or the appropriate kernel) to create a new Jupyter Notebook.
You can now start writing and executing your code in the cells of the notebook. The interface allows you to document your code, visualize data, and explore datasets interactively.

Building Your First Machine Learning Model
In building your first model, we have to take cognizance of the steps in Machine Learning as discussed earlier, which are:
- Import the Data
- Clean the Data
- Split the Data
- Create a Model
- Train the Model
- Make Predictions
- Evaluate and Improve
Now, let's assume a scenario involving an online bookstore where users sign up and provide their necessary information such as name, age, and gender. Based on their profile, we aim to recommend various books they are likely to buy and build a model that helps boost sales.
First, we need to feed the model with sample data from existing users. The model will learn patterns from this data to make predictions. When a new user signs up, we can tell the model, "Hey, we have a new user with this profile. What kind of book are they likely to be interested in?" The model will then recommend, for instance, a history or a romance novel, and based on that, we can make personalized suggestions to the user.
Let's break down the process step-by-step:
- Import the Data: Load the dataset containing user profiles and their book preferences.
- Clean the Data: Handle missing values, correct inconsistencies, and prepare the data for analysis.
- Split the Data: Divide the dataset into training and testing sets to evaluate the model's performance.
- Create a Model: Choose a suitable machine learning algorithm to build the recommendation model.
- Train the Model: Train the model using the training data to learn the patterns and relationships within the data.
- Make Predictions: Use the trained model to predict book preferences for new users based on their profiles.
- Evaluate and Improve: Assess the model's accuracy using the testing data and refine it to improve its performance.
By following these steps, you will be able to build a machine-learning model that effectively recommends books to users, enhancing their experience and boosting sales for the online bookstore. You can gain access to the datasets used in this tutorial here.
Let's walk through a sample code snippet to illustrate the process of testing the accuracy of the model:
- Import the necessary libraries:
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
We start by importing the essential libraries. pandas is used for data manipulation and analysis, while DecisionTreeClassifier, train_test_split, and accuracy_score are from Scikit-learn, a popular machine learning library.
- Load the dataset:
book_data = pd.read_csv('book_Data.csv')
Read the dataset from a `CSV file` into a pandas DataFrame.
- Prepare the data:
X = book_data.drop(columns=['Genre']) y = book_data['Genre']
Create a feature matrix X by dropping the 'Genre' column from the dataset and a target vector y containing the 'Genre' column.
- Split the data:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Split the data into training and testing sets with 80% for training and 20% for testing.
- Initialize and train the model:
model = DecisionTreeClassifier() model.fit(X_train, y_train)
Initialize the DecisionTreeClassifier model and train it using the training data.
- Make predictions and evaluate the model:
predictions = model.predict(X_test) score = accuracy_score(y_test, predictions) print(score)
Make predictions on the test data and calculate the accuracy of the model by comparing the test labels to the predictions. Finally, print the accuracy score to the console.
In this example, we start by importing the essential libraries. Pandas is used for data manipulation and analysis, while DecisionTreeClassifier, train_test_split, and accuracy_score are from Scikit-learn, a popular machine learning library. We then read the dataset from a CSV file into a pandas DataFrame, prepare the data by creating a feature matrix X and a target vector y, split the data into training and testing sets, initialize and train the DecisionTreeClassifier model, make predictions on the test data, and calculate the accuracy of the model by comparing the test labels to the predictions.
Depending on the data you're using, the results will vary. For instance, in the output below, the accuracy score displayed is 0.7, but it may show 0.5 when the code is run again with a different dataset. The accuracy score will vary, a higher score indicates a more accurate model.
Output:
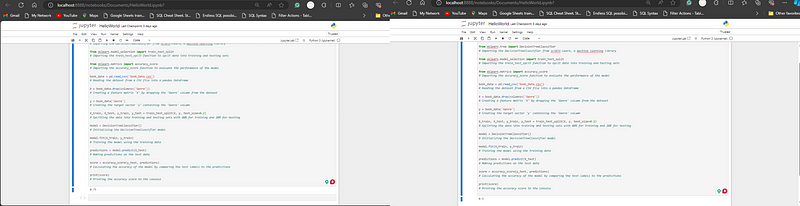
Data Preprocessing:
Now that you've successfully created your model, it's important to note that the kind of data used to train your model is crucial to the accuracy and reliability of your predictions. In Mastering Data Analysis: Unveiling the Power of Fairness and Bias in Information, I discussed extensively the importance of data cleaning and ensuring data fairness. Depending on what you intend to do with your model, it is essential to consider if your data is fair and free of any bias. Data cleaning is a very vital part of machine learning, ensuring that your model is trained on accurate, unbiased data. Some of these ethical considerations are:
Removing Outliers: Ensure that the data does not contain extreme values that could skew the model's predictions.
Handling Missing Values: Address any missing data points to avoid inaccurate predictions.
Standardizing Data: Make sure the data is in a consistent format, allowing the model to interpret it correctly.
Balancing the Dataset: Ensure that your dataset represents all categories fairly to avoid bias in predictions.
Ensuring Data Fairness: Check for any biases in your data that could lead to unfair predictions and take steps to mitigate them.
By addressing these ethical considerations, you ensure that your model is not only accurate but also fair and reliable, providing meaningful predictions.
Conclusion:
Machine learning is a powerful tool that can transform data into valuable insights and predictions. In this article, we explored the fundamentals of machine learning, focusing on supervised and unsupervised learning, and demonstrated how to set up your environment and build a simple machine learning model using Python and its libraries. By following these steps and experimenting with different algorithms and datasets, you can unlock the potential of machine learning to solve complex problems and make data-driven decisions.
In the next part of this series, we will dive deeper into advanced techniques and real-world applications of machine learning, exploring topics such as feature engineering, model evaluation, and optimization. Stay tuned for more insights and practical examples to enhance your machine-learning journey.
Additional Resources:
Programming with Mosh
Machine Learning Tutorial geeksforgeeks
-
 Java的Map.Entry和SimpleEntry如何简化键值对管理?的综合集合:在Java中介绍Java的Map.entry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry apry and Map。 地图。它具有两个通用...编程 发布于2025-06-09
Java的Map.Entry和SimpleEntry如何简化键值对管理?的综合集合:在Java中介绍Java的Map.entry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry和SimpleEntry apry and Map。 地图。它具有两个通用...编程 发布于2025-06-09 -
如何使用FormData()处理多个文件上传?)处理多个文件输入时,通常需要处理多个文件上传时,通常是必要的。 The fd.append("fileToUpload[]", files[x]); method can be used for this purpose, allowing you to send multi...编程 发布于2025-06-09
-
Go语言垃圾回收如何处理切片内存?Garbage Collection in Go Slices: A Detailed AnalysisIn Go, a slice is a dynamic array that references an underlying array.使用切片时,了解垃圾收集行为至关重要,以避免潜在的内存泄...编程 发布于2025-06-09
-
对象拟合:IE和Edge中的封面失败,如何修复?To resolve this issue, we employ a clever CSS solution that solves the problem:position: absolute;top: 50%;left: 50%;transform: translate(-50%, -50%)...编程 发布于2025-06-09
-
Java中假唤醒真的会发生吗?在Java中的浪费唤醒:真实性或神话?在Java同步中伪装唤醒的概念已经是讨论的主题。尽管存在这种行为的潜力,但问题仍然存在:它们实际上是在实践中发生的吗? Linux的唤醒机制根据Wikipedia关于伪造唤醒的文章,linux实现了pthread_cond_wait()功能的Linux实现,利用...编程 发布于2025-06-09
-
如何使用Python的请求和假用户代理绕过网站块?如何使用Python的请求模拟浏览器行为,以及伪造的用户代理提供了一个用户 - 代理标头一个有效方法是提供有效的用户式header,以提供有效的用户 - 设置,该标题可以通过browser和Acterner Systems the equestersystermery和操作系统。通过模仿像Chro...编程 发布于2025-06-09
-
Spark DataFrame添加常量列的妙招在Spark Dataframe ,将常数列添加到Spark DataFrame,该列具有适用于所有行的任意值的Spark DataFrame,可以通过多种方式实现。使用文字值(SPARK 1.3)在尝试提供直接值时,用于此问题时,旨在为此目的的column方法可能会导致错误。 df.withCo...编程 发布于2025-06-09
-
如何正确使用与PDO参数的查询一样?在pdo 中使用类似QUERIES在PDO中的Queries时,您可能会遇到类似疑问中描述的问题:此查询也可能不会返回结果,即使$ var1和$ var2包含有效的搜索词。错误在于不正确包含%符号。通过将变量包含在$ params数组中的%符号中,您确保将%字符正确替换到查询中。没有此修改,PDO...编程 发布于2025-06-09
-
为什么我的CSS背景图像出现?故障排除:CSS背景图像未出现 ,您的背景图像尽管遵循教程说明,但您的背景图像仍未加载。图像和样式表位于相同的目录中,但背景仍然是空白的白色帆布。而不是不弃用的,您已经使用了CSS样式: bockent {背景:封闭图像文件名:背景图:url(nickcage.jpg); 如果您的html,css...编程 发布于2025-06-09
-
如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...编程 发布于2025-06-09
-
如何实时捕获和流媒体以进行聊天机器人命令执行?在开发能够执行命令的chatbots的领域中,实时从命令执行实时捕获Stdout,一个常见的需求是能够检索和显示标准输出(stdout)在cath cath cant cant cant cant cant cant cant cant interfaces in Chate cant inter...编程 发布于2025-06-09
-
如何在无序集合中为元组实现通用哈希功能?在未订购的集合中的元素要纠正此问题,一种方法是手动为特定元组类型定义哈希函数,例如: template template template 。 struct std :: hash { size_t operator()(std :: tuple const&tuple)const {...编程 发布于2025-06-09
-
如何高效地在一个事务中插入数据到多个MySQL表?mySQL插入到多个表中,该数据可能会产生意外的结果。虽然似乎有多个查询可以解决问题,但将从用户表的自动信息ID与配置文件表的手动用户ID相关联提出了挑战。使用Transactions和last_insert_id() 插入用户(用户名,密码)值('test','test...编程 发布于2025-06-09
-
如何从PHP中的Unicode字符串中有效地产生对URL友好的sl。为有效的slug生成首先,该函数用指定的分隔符替换所有非字母或数字字符。此步骤可确保slug遵守URL惯例。随后,它采用ICONV函数将文本简化为us-ascii兼容格式,从而允许更广泛的字符集合兼容性。接下来,该函数使用正则表达式删除了不需要的字符,例如特殊字符和空格。此步骤可确保slug仅包含...编程 发布于2025-06-09
-
找到最大计数时,如何解决mySQL中的“组函数\”错误的“无效使用”?如何在mySQL中使用mySql 检索最大计数,您可能会遇到一个问题,您可能会在尝试使用以下命令:理解错误正确找到由名称列分组的值的最大计数,请使用以下修改后的查询: 计数(*)为c 来自EMP1 按名称组 c desc订购 限制1 查询说明 select语句提取名称列和每个名称...编程 发布于2025-06-09















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









